
Recently, I read this paper “The Platonic Representation Hypothesis” (Huh et al. 2024). The hypothesis states that all deep neural networks–no matter how they are trained, what training dataset they use, or which modalities they operate on–are converging to one shared statistical model of reality in their representation spaces.
This hypothesis is powerful in that it points out a recent trend: good models that generalize well tend to have similar internal representations of the world. Many people found evidence that a feature discovered in one good model probably exists in another good model as well.
Let’s consider a well-known word2vec arithmetic example: “King – Male + Female = Queen”. This kind of relationship has been observed in many models. We can think of this as a sort of geometry: subtracting the vector Male from the vector King and adding the vector Female lands in the close neighborhood of the vector Queen.
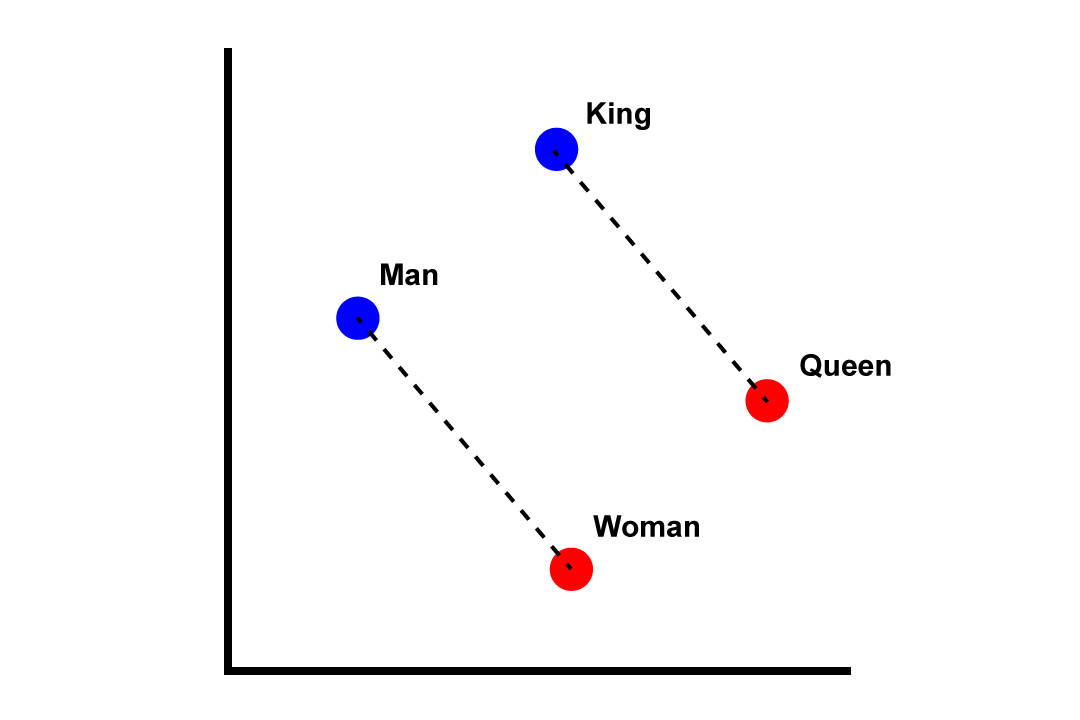
In the hypothesis, the authors proposed that there might exist a “shared model of reality” in which the relationships that between the vectors King and Queen are reflected, and that all deep learning models would eventually converge toward that “shared model”. The differences in representation between models would then be only simple transformations (for example linear) or simply noise.
This is very similar to Plato’s Allegory of the Cave from 375 B.C. Plato points out that all the human knowledge consists merely shadows of a perfect reality. The tree you know and the tree I know are both derived from the ideal “tree”.

I think the hypothesis is partially right, especially when models are not yet universally capable. Currently, the internal representation of good models seem to be converging asymtopotically. However, if we use humans as an analogy, we immediately see that the process is not simply convergent. Diversity is another feature of the evolution. For humans, individual differences exist without doubt and won’t be eliminated anytime soon.
I like the fact that the authors choose “Plato” to name this hypothesis, because today we read Plato’s Allegory of the Cave in a more critical way. There is no ideal “tree” living in an ideal world. Everyone observe different trees and do the abstraction. The process and outcomes are similar enough so that we can communicate, but individual differences are definitely there.
To me, this paper reveals a important trend: good LLMs are becoming more and more similar. This trend is real. And the implication, in my view, is that LLMs are becoming more and more like us. We share the same understanding of the world (since we provide the text and other training materials), and we’ll probably share more behaviors as well.
I think LLMs can be thought of as our brain-children who inherit our abstractions. On the other hand, if we emphasize first principles more strongly, and train models directly on reality or on simulations of reality (such as AlphaZero), then we may produce a “species” of models that are very different from current LLMs and ourselves.
Diversity and similarity are the forever story of complex systems. Let’s see what comes in the future.

Leave a comment